
Reducing time, cost, and overall overhead generated by addressing Common Vulnerability Exposures in your software supply chain can be a constant challenge if the organization’s stakeholders aren’t aligned on how to address CVEs.
As explained during my presentations about “Java and the Open Source ecosystem security”, the lifecycle of a CVE can vary in complexity depending on many internal and external factors in your organization. The way you can handle internal factors is tied to your overall organizational structure, process, and culture, among other factors. But the ones external to you are the ones you need to be aware of and take into consideration when addressing CVEs in Open Source components from your software supply chain. This
Information Overload
The CVE Record Lifecycle [1] contains the six general stages a cybersecurity vulnerability goes through, right from the discovery stage until it gets published. Once it’s published, chances are you sooner or later will know about it if the CVE is related to the component you are currently using in your software supply chain. This notification can be as early in the stage of a development you are currently working on or as late as when your production systems are under attack; the timing will depend on your organization process, technical tooling, risk and security management, among others.
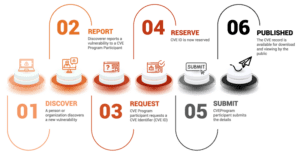
Once you are notified, the first question you should ask yourself is, “Are we really impacted?”. It’s common for CVE’s tooling or scanners to base the matching of a particular CVE using Common Platform Enumeration (CPE™) [2] that includes part, vendor, product, version, and update the specific or range of versions affected by a CVE. Unfortunately, this is not enough information to affirm that the vulnerability really impacts you.
The CVE structure contains references to different official channels where the vulnerability has been discussed and/or addressed. This includes but is not limited to an open source project mailing list, component official release notes, commits references to source code via collaborative version control systems like GitHub, and issue tracking systems like Jira, Github Issues, or Bugzilla. You will be surprised that even after a CVE has been published and a patched component version is available, the conversation can continue via the channel listed above. Therefore, the challenge you now have is to stay up to date with the latest information in order to identify if you are really affected or not.
Sometimes, during the research of information, you can find that a CVE can be activated or mitigated in your component by a configuration flag; other times, you can find there is a mismatch in your tooling that reported a false positive based on the CPE, this often happens when the CPE is updated on the CVE databases, but your security scanner or tooling hasn’t updated its index from those databases. Remember that CVEs can be updated many times after publication. Less often, a CVE can be disputed, showing one more time that cybersecurity vulnerabilities have many external factors that may affect your processes, tooling, and overall organization vulnerabilities lifecycle.
Testing CVE scenarios
The next step after confirming that you are being affected by a CVE is to have a test scenario that can help keep your continuous integration and delivery system and your risk matrix up to date with the latest CVE patch applied. Since testing is one of the challenging areas in IT, proving that your system is affected by a vulnerability can be time-consuming because each Open Source project may have slightly different approaches to CVE’s patching.
The most straightforward scenario you can find is when an exploit is already available for a particular vulnerability, but at the same time, this means that you can be potentially at higher risk than you initially thought. If not available, another option is to check if the project of the affected component included a set of tests you can start to examine towards obtaining your own reproducible scenario. The maintainers, user, and committers exchanges in the mailing list, issue trackers, pull requests reviews, and commit messages can be another source that can provide you with more pieces of the puzzle to enable you to reproduce the vulnerability.
On the opposite side of the spectrum, you can find projects that simply provide the patch to a vulnerability as a commit without even a ticket or association to the CVE, in this scenario, you need to understand what changed in the source code, look for tests (if any) and even debug the component against your software to come up with a partial set of steps that will reveal reproducible scenarios. This is an expensive scenario based on the amount of effort and time required and also has the prerequisite of having in your organization the human capital with the knowledge and resources to perform the investigation.
Constant Updates
CVEs can be updated many times after publication, and if the update is related to the CPE [2], then you need to be prepared to start the process all over again right from the scanning or discovery phase in your security process and the point shared above. There can be an update that even leads to a CVE being disputed, showing one more time that cybersecurity vulnerabilities have many external factors that may affect your processes, tooling, and overall organization vulnerabilities lifecycle.
Starting to address a CVE for the first time can be challenging due to the three factors we have covered so far and the internal and external factors attached to it. In the second part of this series, we will cover how to prioritize, inventory, and monitor a CVE to increase your peace of mind when new CVEs are present in your software supply chain.
How to prioritize and monitor vulnerability remediation
The amount of notification and information by vulnerability scanners can be overwhelming even now with the rise of tooling focused on the detection of CVEs across organizations’ software supply chains. Balancing the among of effort and resources vulnerability remediation takes between the business priorities; the following are strategies you can use to better prioritize, inventory, and monitor the CVEs reported in your security process and DevSecOps tooling.
Prioritize CVEs
Many resources can help you to prioritize the CVE’s processing in your organization. The first one is based on publicly available resources like the Known Exploited Vulnerabilities Catalog run by the Cybersecurity & Infrastructure Security Agency -CISA-. This actively updated database helps federal agencies keep up with exploited vulnerabilities, and the information is available in different formats like CSV and JSON. This can help you to balance the priority of a set of CVE’s based on your organization’s workflow and the risk associated with it based on the exploitability of the vulnerability.
Many tools and scanners have the ability to provide you with filtering based on CVEs severity, and combined with the Known Exploited Vulnerabilities Catalog, you can have two more axes in your software supply chain risk matrix.
Inventorying and monitoring CVEs
As you have seen so far, managing CVE’s data and metadata requires a lot of effort. The need for a portfolio of your components, their CVE’s, internal notes, and references to your test scenarios within your CI/CD systems becomes evident. Many tools in the market can provide you with these capabilities, and with the increase in popularity and adoption of the Software Bill of Materials (SBOM), the OWASP® Foundation provides an Open Source response to improve the identification and reduce risk in the software supply chain with the project Dependency-Track.
Operational Software Bill of Materials
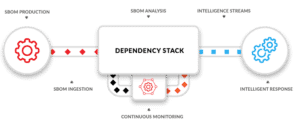
We can cover the SBOM topic in detail in a different article, but it is worth mentioning that the data by itself doesn’t provide much value on how you address your CVEs within your organization if you don’t have the help needed to have the vulnerability metadata up to date, organized and available as a self-service right from the moment a developer is adding functionality in their workstations, up to the deployment and staging of the component in your software supply chain. Integration is the key challenge when you already have invested in tooling and processes, and therefore, avoiding technical debt and operational costs are two main points to keep in mind when you design how best to inventory and monitor your CVE process.