
One of the common issues we run into with ActiveMQ, is the issue of kahadb log files not being cleared up, leading to the system potentially running out of disk space.
There are a few reasons why these log files are not cleaned up:
- It contains a pending message for a destination or durable topic subscription
- It contains an ACK for a message which is in an in-use data file – the ACK cannot be removed as a recovery would then mark the message for redelivery
- The journal references a pending transaction
- It is a journal file, and there may be a pending write to it
More often than not, this is caused by the log file containing messages that have not yet been consumed (number 1 in the list above).
We recently encountered this with a customer, who had a very large number of unconsumed messages across multiple destinations. When they purged over a million messages from one of their queues, not only did the KahaDB logs not get cleared up, but several gigabytes of additional log files were created, consuming more disk space.
So, why is that? Let’s take a look at what’s going on in KahaDB to better understand it.
https://activemq.apache.org/why-do-kahadb-log-files-remain-after-cleanup
KahaDB structure
First off, a quick disclaimer – this article is not intended to give a detailed description of the inner workings of KahaDB. That could fill several chapters of a book (if you’re looking for a good ActiveMQ book, I recommend this one: https://www.manning.com/books/activemq-in-action). I’ve deliberately simplified KahaDB here, and will try to make some comparisons to SQL, which will hopefully help explain a little about what’s going on and perhaps clear up some misconceptions.
KahaDB uses a folder on the filesystem, and has two types of files, one that ends with .data, and a set that ends with .log. The actual messages are held in the log files, and the .data file provides an index to that data. The series of log files is called a journal.
I like to think of the journal as a linked list, or stream of commands. Here’s a very simple example:
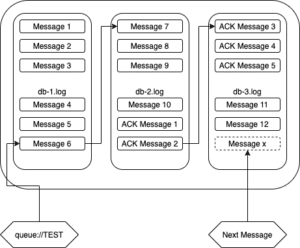
In this example, 10 messages have been added to a queue called TEST, 5 of them have been consumed, and a further 2 messages have been added to the queue.
The item written to the journal are commands. There are commands to persist a message, acknowledge a message and start/commit/rollback transactions amongst others.
A key property of a command in a journal log is that it is immutable. When a message is consumed, the command that added the message remains, unchanged, in the journal. It isn’t overwritten, or zeroed-out. When it is consumed, an acknowledgment command for the message is appended to the journal.
Let’s contrast this to the same scenario in a SQL database. Here, the data in the ACTIVEMQ_MSGS table looks like this:

What you can see here, is that the messages that have been consumed in ActiveMQ have been deleted from ACTIVEMQ_MSGS table (note that IDs 1-5 are not present).
Coming back to the KahaDB example, if message 6 from the TEST queue is consumed, the db-1.log file can finally be cleaned up, as all its messages have been consumed.
Multiple destinations
In our simple example, we only have one destination. If we consumed all the messages in our TEST queue (or purged the queue), the acknowledgment commands would be added to the journal, and the journal files would be cleaned up. So, how does this explain the situation where the log files weren’t cleaned up, and the journal grew by several GB when messages were purged?
The answer is that there were multiple queues with unconsumed messages. The journal is a single stream, with messages and acknowledgments for all destinations written to it. So where we have 2 queues, the journal might look like this:
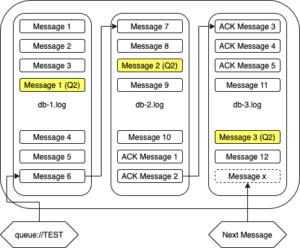
The messages highlighted in yellow are for a second queue. If these are not consumed, they’ll prevent all three db log files from being cleaned up, even if all the messages in the first queue are consumed. If we purge the first queue, our journal will look like this:
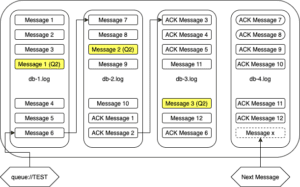
As you can see, the pending messages in yellow prevent the first three log files from being released, and the acknowledgment messages have caused the journal to roll over to a fourth log.
Solutions
If you’re running into this scenario, switching to mKahaDB may be worth considering. This allows you to use different KahaDB folders for different destinations. More information on configuring this is available here: https://activemq.apache.org/kahadb.html (scroll down to “Multi(m) kahaDB Persistence Adapter”). Simple configuration may look like this:
<persistenceAdapter> <mKahaDB directory="${activemq.base}/data/kahadb"> <filteredPersistenceAdapters> <!-- kahaDB per destinations --> <filteredKahaDB perDestination="true"> <persistenceAdapter> <kahaDB journalMaxFileLength="32mb"/> </persistenceAdapter> </filteredKahaDB> </filteredPersistenceAdapters> </mKahaDB> </persistenceAdapter>
If your message volumes are low, consider using SQL persistence. KahaDB offers better throughput, so this advice may seem a little controversial. With SQL, however, it’s easier to peek into the data store with your database tools to see what’s going on.
The root cause here is messages not being consumed. Check your DLQs to ensure messages aren’t piling up there, and consider adding expiry times to your messages so they are moved to the DLQ if they are not consumed in a timely manner.
One Comment